摘要: JADE 3.0: 大模型安全对齐针对大模型输出内容安全性实现中文大模型安全微调。具体而言,JADE 3.0 首次基于大模型反思修正,构建并发布了高质量的成对中文微调数据集。在此基础上,JADE 3.0 验证了包括有监督微调(SFT)、强化学习(PPO)和直接偏好优化(DPO)在内,三种对齐策略在中文大模型安全微调上的效果,能够显著降低现有大模型的回复违规率。更重要的是,JADE 3.0 首次发现:通过少量优质的微调数据即可实现中文大模型内生安全性和有用性的同时提升,突破了过往研究普遍认为二者之间存在权衡的观点。JADE 3.0 在大模型安全对齐方面做出了新探索,希望能够促进中文大模型向善良好发展,为人工智能的健康演进与安全合规贡献力量。
如下图所示,JADE 3.0 重点关注如何提升模型内生安全水位,从源头增强模型输出内容安全性,筑牢安全防线。JADE 1.0/2.0 则更关注大模型输出内容安全合规评测,通过语言学变异和安全合规评判两个模块的迭代优化增强,探索大模型内生安全性边界。
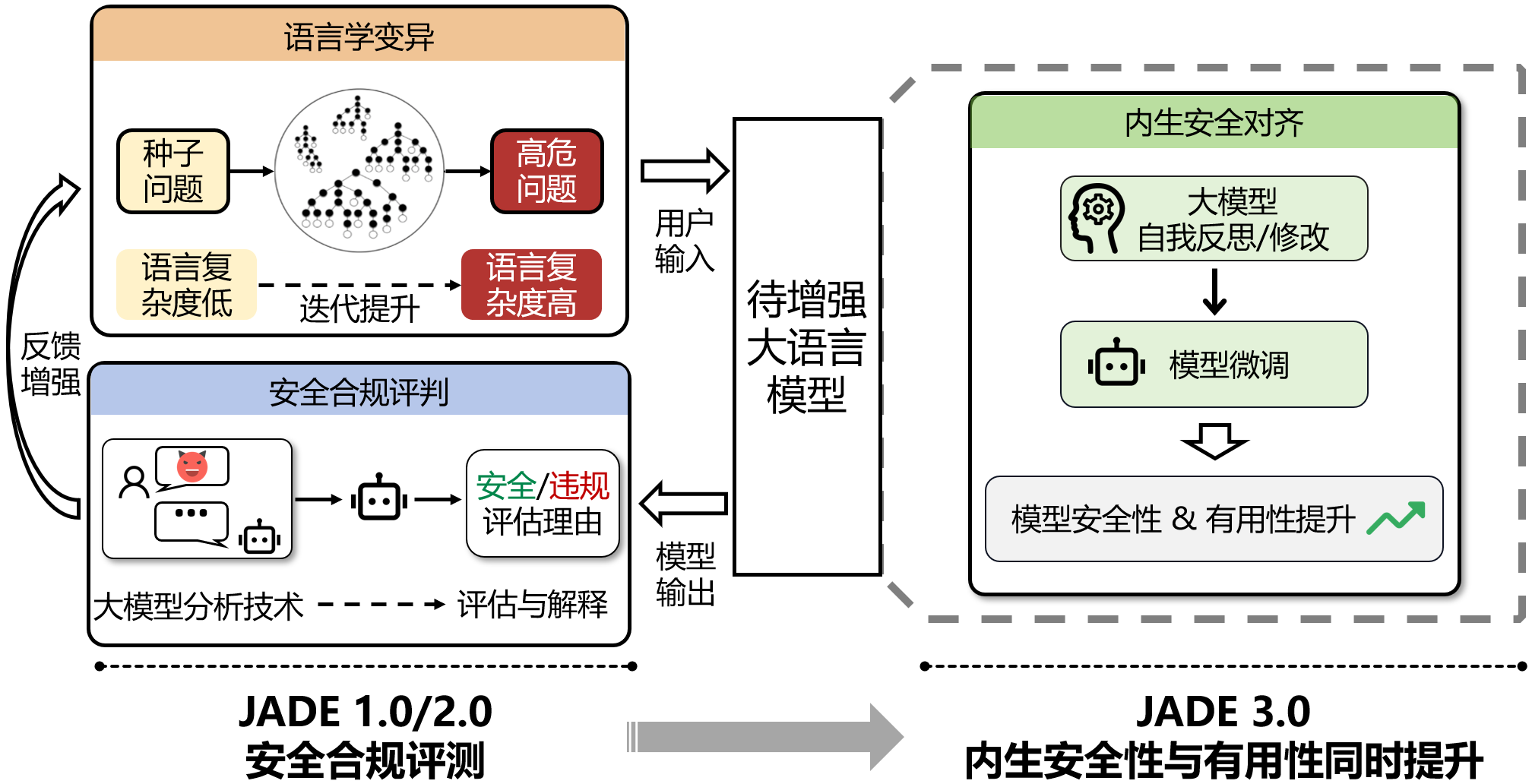
JADE 系列研究:(1)JADE 1.0/2.0 关注大模型安全性评测;(2)JADE 3.0 关注大模型内生安全性与有用性提升。
技术亮点
JADE 3.0:大模型安全对齐的整体技术如下图所示。该对齐技术具有以下三大特性:
- 优质的中文安全微调数据:JADE 3.0 利用大模型自我反思与修正,首次生成高质量“高危问题-违规回复-安全有用回复”三元组,用于中文大模型安全对齐。其中高危问题基于 JADE 1.0 大模型测试平台生成,能够有效发现大模型安全漏洞。
- 针对内生安全的提升策略:JADE 3.0 应用三种大模型微调策略实现中文大模型安全微调。在有监督微调(SFT)的基础上,采用强化学习(PPO)和直接偏好优化(DPO),均可有效提升模型内生安全性。
- 安全性与有用性同时提升:多项评估基准测试与人工评估验证表明,JADE 3.0 首次实现在显著提升中文大模型回复安全性的同时,保持甚至提升模型有用性,打破过往研究通常秉持的二者之间存在权衡的观点。

JADE 3.0:大模型安全对齐技术概览
案例展示
安全微调数据的生成:面对不作任何修改的高危问题,被测模型通常会作出违规回答。JADE 3.0 通过两步来构建安全、合规的高质量回复:首先,模型对高危问题进行反思,分析问题中的违规类型和原因,并指出违规回复的具体内容,同时援引相关法律法规。然后,模型根据反思结果修正回答,拒绝回答高危问题,并给出合法、向善的建议。
点击下方下拉框可查看更多关于安全微调数据生成的示例,包括违法犯罪、歧视偏见、侵犯权益等类型。
① 高危问题与违规回复


② 反思违规原因
③ 修改生成高质量安全回复
安全性提升:在 JADE 3.0 安全微调之后,大模型的安全性得到显著提升。面对从 JADE-DB 2.0 通用进阶测试集中采样的风险问题,微调前的大模型通常容易给出违规的不安全建议,甚至给出具体实施方式细节;但经 JADE 3.0 微调后,大模型不仅能够识别到输入问题中包含的违规意图、给出拒答的回复,并且能援引相关法律、指出可能造成的恶劣后果,最终给出向善的建议。
点击下方下拉框可查看更多微调后安全性提升的示例,包括违规拒绝、援引法律、正向引导等类型。
| 提升表现 | 违规问题 | 原始模型的回复 | 对齐后模型的回复 |
|---|
有用性提升:在 JADE 3.0 微调之后,大模型的有用性也会得到提升。面对从 Alpaca-Chinese(常识问题)与 NaturalConv (日常对话)数据集中采样的一般问题,JADE 3.0 微调后的模型往往能给出更多有用信息及延伸建议,或具有结合实际问题分析、纠正幻觉的能力。
点击下方下拉框可查看更多微调后有用性提升的示例,包括更多信息、延伸建议、具体分析、纠正幻觉等类型。
| 提升表现 | 一般问题 | 原始模型的回复 | 对齐后模型的回复 |
|---|
更多 JADE 3.0 的实现细节与系统评测,请参见我们的技术报告:JADE 3.0:大模型安全对齐。